
How computers see our world is a truly fascinating topic that gets really deep really quickly as you start diving into it. I got first introduced to this topic when I was 16, in my high school there were some afternoon sessions for ‘bonus points’ about various topics and one of my teachers’ eldest son was a researcher in the image recognition field so he was invited to give us a really simplified 45 mins summary of his work and challenges. He did an amazing job and showed important practical uses of his own research that made almost all of us instantly interested. Of course, back then me and my friends knew nothing about AI, neural networks, convolutional algorithms or Machine Learning and the whole field came a long way since then, we have computational power and resources available now that our lecturer could only have dreamt of at that time.
What is image recognition?
Image Recognition is the task of identifying objects of interest within an image and recognizing which category that object belongs to. For us humans, this seems like a really natural thing that our brain with its immense “computational capacity” makes seem easy but it turns out it is a highly complex task for machines to perform when we start to translate everything our brain does into computer code and it requires some quite significant processing power too.
A digital image is a representation of visual data by a series of pixel values in a grid-like fashion. The values on the grid represent how bright and what color each pixel should be and the higher the resolution goes, the more bit depth and colors..etc. we have, the more data we have to work with. Our goal is to have an image as the input and then classify data into one bucket out of many. These class labels are provided by our pre-defined classes. So for example, our computer can identify that there is a dog on the picture and provide it as an output.

One of the often used examples is OCR, so optical character recognition. Here the input is a handwritten (or printed) text, the algorithm can identify the characters as part of the picture and give back a digital text file thus eliminating typing manually and enabling for example machine translation of old text you only have on paper. This can be done for any alphabet and a wide variety of writing styles so it might save some significant struggles when trying to interpret your doctor’s handwriting.
How does it work?
The process of building an image recognition model is no different from the process of other machine learning modeling and has four basic steps:
- Step 1: Extract pixel features from an image
- Step 2: Prepare class-labeled images to train the model
- Step 3: Train the model to be able to categorize images
- Step 4: Recognize (or predict) a new image to be one of the categories
Gathering and organizing the data requires by far the most work, I would say 85% of the effort goes into this and the remaining 15% is divided between building and testing the predictive model and using our model to recognize images, where the latter is probably the smallest part in terms of efforts needed.

Usually, there is some basic pre-processing required before we can start working on the data (for example re-sampling, noise reduction, contrast enhancement ..etc.) so we can make sure we will get the best results. Once this is done we can move forward with the feature extraction.
This typically includes identifying:
- Lines, edges and ridges.
- Localized interest points such as corners, blobs or points.
- More complex features may be related to texture, shape or motion.
Once our images are converted to thousands of features, we can start using them for training our model as we know the corresponding image labels. So, for example, we know the characteristic image features of cats now. The more images we can use for each category, the better our model can be trained. Here we already know the category that an image belongs to and we use them to train the model.
This is called supervised machine learning and by using labeled inputs and outputs, the model can measure its accuracy and learn over time. Once a model is trained, it can be used to recognize (or predict) any unknown image. This unknown image also goes through the pixel feature extraction process.
You are already helping Google AI Image Recognition
As an interesting sidenote, please let me mention that you were already part of such model training even if perhaps a bit unknowingly. Google has countless reasons to want to train AI to recognize objects in images. More accurate Google Maps results, better Google Image Search results, …etc. For example, at the moment I am using a Pixel 6 and my Google Photos library has a neat little trick, I can type in a search word like ‘electric guitar’ and it will show me all my pictures with guitars on it (which I have quite a few of). Also, probably more importantly for mankind, they also want to make sure that your driverless/self-driving car doesn’t hit anything.
Now, you know how occasionally you’ll be prompted with a “Captcha” when browsing the internet, to prove that you are a human?
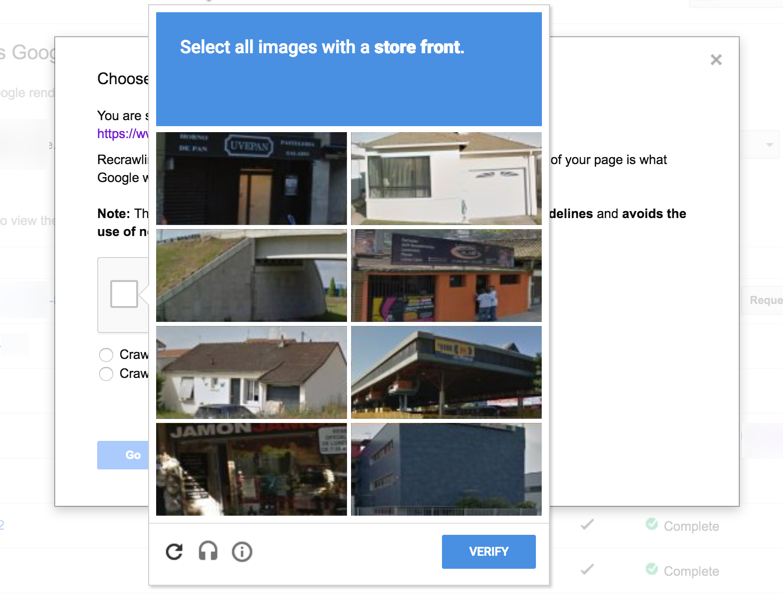
It is hugely convenient for Google that it has hundreds of millions of internet users at its disposal who can contribute by using Recaptcha to essentially label images. Every time we need to prove on the internet that we are human we are building a database that can be later used for such purposes.
So when Recaptcha asks you to identify street signs and you do exactly that you’re essentially contributing to piloting a driverless car somewhere, at some point in the future.
Convolution Neural Networks – CNN
Traditional machine learning algorithms and models like Support Vector Machines, Bag of Features Models or the face recognition favorite Viola-Jones Algorithm have been the gold standards for image recognition for many years. However, the rapid increase in the processing power of GPUs (Graphical Processing Unit) made them powerful enough to support the massively parallel computational tasks that the newer neural networks require and the performance of these neural networks greatly surpasses the traditional algorithms.
A Convolutional Neural Network, also known as CNN, is a class of neural networks that is specifically designed to process data that has a grid-like topology which makes it ideal for image processing. The network layers of CNNs are different from the typical neural networks and divided into four building types: convolution, the ReLUs, the pooling, and the fully connected layers. In our brain, each neuron has its own receptive field and is coupled to other neurons so that the full visual field is covered. Similar to that the CNN also has a number of layers, designed so that simpler patterns (lines, curves, etc.) are detected first, followed by more complicated patterns (faces, objects, etc.).
- The first step that CNNs do is to create many small pieces called features. Each of these features characterizes some important shape of the original image. Each feature is scanned through the original image and if there is a perfect match, a high score gets assigned to that area. Similarly, if there is no match the score is zero and if there is a low match, a low score gets assigned. This scoring process is called filtering. This act of trying every possible match by scanning through the original image is called convolution. These filtered images are stacked together to become the convolution layer.
- The next is the Rectified Linear Unit (ReLU) which is fairly typical for neural networks. It basically makes sure that math will behave correctly by rectifying any negative value to zero.
- Pooling shrinks the image size through a step-by-step process which produces a new stack of smaller filtered images.
- As the final step we split the smaller filtered images and stack them into a single list. The values in the single list predict a probability for each of the final values 1,2,…, and 0. This part matches the output layer in other typical neural networks.

Read more at: https://viso.ai/deep-learning/yolov7-guide/
CNN’s create the convolution layer to retain information between neighboring pixels and that is its main advantage compared to other typical NNs that stack the original image into a list and turn it to be the input layer. In Deep Image Recognition, Convolutional Neural Networks even outperform humans in tasks such as classifying objects into fine-grained categories such as the particular breed of dog or species of bird on the picture.
Image Recognition through APIs and the Cloud
Nowadays there are a number of excellent quality services available that provide an easy way to perform picture recognition through cloud-based APIs:
These are ideal for tasks like object or face detection, text recognition, handwriting recognition.. etc. Before picking the best provider it is important to look into if data offloading is allowed or not (privacy, security, legality..etc. concerns) and to check connectivity, bandwidth, robustness, latency, data volume and costs metrics.
To overcome the limits of pure-cloud solutions, recent image recognition trends focus on extending the cloud by using Edge Computing with on-device Machine Learning.
I recommend this detailed comparison if you would like to learn more about the pre-built options.
Use cases for Object and Image Recognition
Face Analysis
Face detection, face pose estimation, face alignment, gender recognition, smile detection, age estimation, and face recognition using a deep convolutional neural network are all widely available and used for example when presenting our passports at some hight traffic places. However, with our most advanced systems, we are even able to identify intentions, emotional and health states and some social media tools even aim to quantify levels of perceived attractiveness with a score.
Medical Image Analysis
Medical image analysis is one of the most highly profitable subsets of artificial intelligence today. Visual recognition technology is widely used for example, in the identification of melanoma, a deadly skin cancer. Deep learning image recognition software also allows tumor monitoring across time, for example, to detect changes in different scans or in projects like COVID-Net which is designed for the detection of COVID-19 cases from chest X-ray images.
Animal Monitoring
As a strongly growing trend, livestock is being monitored remotely through AI tools for disease detection, anomaly detection, compliance with animal welfare guidelines, industrial automation… etc. providing many advantages to its adopters.
Object detection for Earth Observation Data
Public sector companies like the Swiss Federal Railways (SBB) are not necessarily first associated with digital innovation but offering a high-quality service to 1.18 million passengers and 210,000 tons of cargo over 3,000 kilometers of railways daily requires both advanced planning and clever use of modern technology. In order to improve service, run a safe operation, and boost infrastructure longevity SBB maintains a detailed countrywide database of various objects related to its railway network (e.g. manholes, signals, canals, etc.) but the irregular nature and inaccessibility of these objects make it impossible to track and maintain an up to date database of them through any kind of manual process. However, with modern Machine Learning algorithms at hand, these objects are easily spotted in aerial imagery (combined RGB images from drones, helicopters and satellites) and can be automatically cataloged with a 93% accuracy.

Geospatial data is in a unique position to positively impact Environmental, Social, and Governance (ESG) goals around the world which are becoming increasingly more pressing. As a somewhat unexpected use case, for example, it turned out recently that tracking marmots can accurately represent biodiversity and help tremendously with conservation efforts since they play a vital role for the functioning of the ecosystem and the habitat of other species.
Marmot burrows are visible on satellite images thanks to the mounds of soil that the rodents make as they tunnel into the ground. By analyzing historical pictures from the CORONA satellite system (US Air Force, CIA, and private industry partners) that were declassified in 1995 and comparing them to recent high-resolution images, it was possible to enable a new understanding of how farming is affecting this species and highlight the long-term environmental impact of human activities. This interplay between agriculture and biodiversity enables often overlooked changes to be observed directly via satellite imagery and a fitting ML process.
If you are interested in image processing or Machine Learning in general, please feel free to reach out to us, we would love to have a chat and nerd out together.


